C'est l'heure du débriefing des journées SQL et commençons déjà avec les remerciements qui s'imposent :
- Merci François pour cette session co-animée avec toi, c'est un joli cadeau que tu m'as fait. J'espère qu'on a rendu le MDX et le DAX plus amusants (c'est le terme que tu emploierais assurément) et moins obscurs aux yeux du public.
- Merci à ce public d'avoir répondu présent sur notre session qui promettait d'être technique...
- ..., et d'avoir répondu présent sur l'événement en général
- Merci au board GUSS (bon je vais pas vous citer personnellement car on aura l'occasion de le faire en live, mais vous m'en voudrez certainement pas si je dis quand même un bravo à Djeepy pour le boulot abattu, il le mérite bien)
Un petit retour sur les sessions auxquelles j'ai pu assister (étant désormais presqu'en province, vous constaterez qu'elles sont plutôt de l'après-midi) :
Cloud Privé :
Une bonne surprise. J'ai suivi Florian sans avoir lu le contenu de la session et j'ai cru un moment qu'elle ne me concernait pas trop. Mais finalement, elle donnait une vision intéressante sur la création d'un catalogue d'offre de service (ici sur un cloud privé),et donnait des principes pouvant s'appliquer à tout type d'offre. Ce ne fut pas du temps de perdu.
1 an de Tabulaire :
Session présentée par Erwan et Aurélien toujours très pro. Retour sur le mode tabulaire dans SSAS. J'avoue que j'au eu peur un moment qu'il recoupe toutes les démos DAX qu'on avait prévu avec François. Mais ils se sont arrêté à temps :p Cool le petit focus sur la sécurité dont on n'a pas eu le temps de parler le lendemain.
Modélisation Dimensionnelle :
Là ce n'était pas une surprise, mais une confirmation de la session de l'année dernière. Charles-Henri et Florian nous ont fait une présentation toujours aussi sympa des concepts de la modélisation multidimensionnelle pour la BI.
Bien joué les gars, vivement le chapitre 3.
Processing SSAS :
Grosse performance de Patrice sur le sujet. On sent qu'il a décortiqué le produit dans tous les sens, car le sujet et les questions du public étaient vraiment pointus.
Patrice ,comme on savait grâce à ton bouquin que tu avais déjà désossé SSIS, tu nous montres quand ta maîtrise de SSRS ? ;)
Data-Viz, ergonomie et storytelling :
Une session sympa pour finir les deux jours avec Olivier Courtois et Caroline Goulard sur le phénomène en vogue du moment : la datavisualisation. Une présentation très bien rodée, on sent l'expérience, à la fois sur le sujet et à la fois dans la communication.
Voilà les Journées SQL Server 2012 sont finies, vivement l'année prochaine. C'est super de pouvoir compter sur la communauté pour faire de cette événement le plus grand rassemblement d'experts SQL Server de France.
On attend vos retours maintenant pour continuer à nous améliorer.
mercredi 12 décembre 2012
mercredi 14 novembre 2012
Journées SQL Server 2012, les 10 & 11 Décembre 2012

Quelques nouvelles du front concernant les Journées SQL Server 2012. Les dates sont posées et connues : ce sera les 10 & 11 Décembre 2012. On met donc une petite croix dans son calendrier.
Les inscriptions sont ouvertes également. A noter que comme l'année dernière, l’évènement reste gratuit, mais l'achat d'une lunch box pour le déjeuner est proposée en option.
Les Journées SQL, c'est, en plus de suivre des sessions intéressantes, l'occasion de croiser la communauté et discuter avec les intervenants qui savent rester accessibles. A ce sujet, n'hésitez pas à consulter le dernier article de Florian sur le "comment pratiquer la communauté".
Dernière news et pas des moindres, j'aurais la chance d'animer une session avec l'excellent François Jehl autour du DAX et du MDX, le mardi à 14h.
Une seule adresse à retenir, tout y est : JSS2012
mardi 21 août 2012
AfterWork BI du GUSS le 27 Août 2012
Vous rentrez de vacances ? Vous y partez prochainement ? Vous êtes restés coincés au mois d’aout à Paris.
Quoiqu’il en soit, venez partager un cocktail de vacances avec la communauté SQL Server.
3ème AfterWork du GUSS,
…sur un air de vacances
…sur un air de vacances
Lundi 27 août, 19h00
MAJ: Le lieu change
MAJ: Le lieu change
The Frog & Princess
(sous réserve d’ouverture)

(sous réserve d’ouverture)
9 rue Princesse, Paris
(métro Odéon ou Mabillon)
(métro Odéon ou Mabillon)
Le thème ? Soleil, plage et farniente, partage de nos photos de vacances… ?
Plus sérieusement, presque tous les spécialistes BI seront présents donc le thème sera :
La BI, tout simplement
Venez discuter avec nous, leur poser des questions et connaitre leur avis sur les dernières actus décisionnelles.
lundi 13 août 2012
Lancement des Journées SQL Server 2012

A peine les Journées SQL Server 2011 étaient terminées que vous étiez nombreux à nous demander de remettre cela l’année suivante.
Nous avions nous aussi cela à l’esprit et nous avons lancé l’organisation d’une nouvelle édition il y a quelques semaines déjà.
Il y a encore du travail pour mettre au point cette édition 2012 des Journées SQL Server mais nous pouvons néanmoins commencer à vous en dire un tout petit peu plus, comme le fait qu’elle aura lieu à Paris en décembre.
Afin de s’aligner au plus près de vos attentes, nous avons réalisé un sondage pour nous aider dans nos choix.
Cela ne prend pas plus de 3 minutes montre en main donc cliquez sans plus attendre (le sondage est également compatible smartphone).
Et pour être au courant des dernières infos sur les Journées SQL Server 2012, nous sommes en train de vous concocter un mini-site dédié. Une seule adresse à retenir :
Et surtout, utilisez sans modération les réseaux sociaux : le hastag est #jss2012
Toute l'équipe GUSS

mercredi 18 juillet 2012
[Office 15] Excel 2013 : PowerPivot et PowerView en natif
Hier avait lieu la présentation et la mise à disposition de la preview d'Office 15 (qui s'appellera Office 2013).
Ça se passe par ici pour la télécharger :







Ça se passe par ici pour la télécharger :
Pour les consultants BI que nous sommes, c'est l'occasion de voir les nouveautés d'Excel, outil de reporting par excellence. Et les premières impressions sont plutôt bonnes et rassurantes.
PowerPivot
L'équipe office a donc intégré PowerPivot en natif. Il est vu comme un add-in dans la page d'options d'Excel.

Malheureusement, je n'ai pas pu tester plus en détail, car j'obtiens un message d'erreur dès le clic sur "Manage". J'ai eu beau réinstaller plusieurs fois la preview, j'obtiens le même message (PowerPivot is unable to load the Data Model). On mettra ça sur le compte de la pré-version. MAJ : en installant PowerPivot pour Excel 2010, ça a l'air fonctionnel, mais j'ai deux onglets POWERPIVOT dans le ruban (apparemment un 2010 et un 2013).

PowerView
Même chose que pour PowerPivot, l'équipe a intégré PowerView de manière native, comme un add-in.

Et PowerView est fonctionnel : à l'import classique des données, la dernière boîte de dialogue demande si l'on souhaite intégrer ces données dans un rapport PowerView.

Cela ne marche pour l'instant toujours qu'avec un modèle Analysis Services Tabular (on espère que c'est une limitation due à la pré-version).
Cela ouvre un onglet Excel spécifique en Silverlight avec un menu dans le ruban POWERVIEW.

On peut ensuite commencer à créer sa première analyse.
Une dernière surprise de la preview que vous pourrez constater dans la copie d'écran qui suit : l'intégration de la cartographie dans PowerView, qui manquait cruellement dans la précédente version :

Dans l'exemple précédent, PowerView a matché tout seul les villes par leurs noms (à l'aide Bing Maps), mais on constate également la possibilité de mentionner les latitudes et les longitudes.
Conclusion :
Cette pré-version d'Excel 2013 est vraiment intéressante (elle l'aurait été plus si j'avais réussi à faire fonctionner PowerPivot), avec l'intégration de ces deux fonctionnalités en natif.
L'ajout de PowerView est un point également très important quand on connait la méthode de déploiement actuelle de l'outil (lourde à l'installation et à l'utilisation via Sharepoint). De plus l'ajout de nouveautés comme la cartographie ne peut être que bénéfique à l'outil pour s'imposer face à la concurrence.
mercredi 11 juillet 2012
[SSAS 2012] Croiser les niveaux fins des dimensions avec Analysis Services en mode Tabular
Après deux articles sur les termes en vogue du moment, un petit retour chez Microsoft s'impose, et notamment sur SQL Server 2012 sorti cette année.
La nouvelle version d'Analysis Services a apporté un nouveau mode qui provient directement de PowerPivot : le mode Tabular.
On ne reviendra pas sur les différences entre les versions Tabular et Multidimensionnal (toutes deux disponibles dans SQL Server 2012), ni sur le mode à adopter suivant les projets, de nombreux articles de blogs en parlent. De plus cela a fait l'objet d'une session aux TechDays de cette année (lien).
On va s'intéresser ici aux performances lors de l'interrogation d'un cube au format Tabular. En effet, ce mode a aussi été introduit pour répondre à la problématique d'interrogation des données fines via un cube.
Avant la sortie de SQL Server 2012, la réponse typique du consultant lorsque le client demandait un rapport croisant plusieurs niveaux fins de plusieurs dimensions était : "un cube Analysis Services n'est pas fait pour ça" (note de l'auteur : ce qui en soit n'est pas faux).
On va donc effectuer un petit test rapide :
On crée deux cubes "identiques" en multidimensionnel et en tabulaire : un cube avec une mesure CA, 3 dimensions (client, produit et magasin) et 1 million de lignes.

Sur ces cubes on va appliquer la requête MDX suivante (au nommage des objets entre les deux cubes près) :





La nouvelle version d'Analysis Services a apporté un nouveau mode qui provient directement de PowerPivot : le mode Tabular.
On ne reviendra pas sur les différences entre les versions Tabular et Multidimensionnal (toutes deux disponibles dans SQL Server 2012), ni sur le mode à adopter suivant les projets, de nombreux articles de blogs en parlent. De plus cela a fait l'objet d'une session aux TechDays de cette année (lien).
On va s'intéresser ici aux performances lors de l'interrogation d'un cube au format Tabular. En effet, ce mode a aussi été introduit pour répondre à la problématique d'interrogation des données fines via un cube.
Avant la sortie de SQL Server 2012, la réponse typique du consultant lorsque le client demandait un rapport croisant plusieurs niveaux fins de plusieurs dimensions était : "un cube Analysis Services n'est pas fait pour ça" (note de l'auteur : ce qui en soit n'est pas faux).
On va donc effectuer un petit test rapide :
On crée deux cubes "identiques" en multidimensionnel et en tabulaire : un cube avec une mesure CA, 3 dimensions (client, produit et magasin) et 1 million de lignes.


Les résultats obtenus sont les suivants :
Multidimensionnel : 28s pour l'exécution de la requête :

Tabulaire : 29s pour l'exécution de la requête :

Mais alors finalement, il n'y a pas de différence selon le moteur utilisé ?
En fait la différence se fait par rapport au langage utilisé : MDX versus DAX. Et le DAX ne peut être utilisé (aujourd'hui) qu'avec les modèles tabulaires.
Si vous attaquez votre cube en MDX, vous ne constaterez que peu de différence de performance entre les deux modes. En revanche si vous traduisez votre requête MDX en DAX sur votre modèle tabulaire, vous allez constater une nette amélioration.
Sur mon modèle tabulaire, j'exécute la requête suivante (qui renvoie le même résultat que ma requête MDX) :

On obtient une durée d'exécution de 9s (Notez que c'est à 1s près le temps d'exécution de la requête SQL pour sortir le même résultat sur les tables sources) :

On constate bien le gain appréciable de performance obtenu.
En conclusion si vous avez opté pour le mode multidimensionnel, pas de changement d'attitude à avoir, c'est encore le langage MDX que vous devrez utiliser (du moins pour l'instant).
En revanche si vous avez opté pour le mode tabulaire, il peut être vraiment intéressant de se pencher sur le langage DAX dès l'instant où vous interrogez des données fines dans les dimensions.
mardi 10 juillet 2012
Big Data : Qu'est-ce que c'est ?
Après DataViz, un autre terme en vogue en ce moment, BIG DATA.
Alors une première remarque concernant Big Data : ce n'est pas une technologie précise, mais plutôt un concept qui désigne des ensembles de données extrêmement volumineux. Et derrière ce concept se cache donc différentes technologies et différentes problématiques tels que le stockages à travers des systèmes de fichiers (chose aujourd'hui mature et relativement transparente pour un utilisateur de bases de données relationnelles), et la manipulation de ces données.
Big Data est apparu pour répondre à la problématique des 3V (Velocity, Volume, Variety), problématique commençant à essouffler les SGBDR classiques, vu l'explosion des volumes de données lors de la dernière décennie.
Stockage de Fichiers
Le stockage des données s'effectue via des systèmes de fichiers distribués tels que Google File System (GFS) pour Google ou Hadoop Distributed File System (HDFS) pour Hadoop. Pourquoi avoir redéveloppé un système de fichiers et ne pas utiliser une base de données relationnelle classique à ce niveau là ? J'avoue que la question est ouverte, les SGBDR étant matures sur les clusters. Une réponse est peut-être de ne pas vouloir transformer et modifier les données avant stockage vu la volumétrie, donc gagner du temps. Cela permet de garder le format initial des données et donc de répondre aux problématiques de vitesse, volume et variété (3V).
Manipulation de données
Ici on retrouve les programmes qui effectuent les traitements ou les calculs sur les données, toujours via un processus de distribution et de parallélisation, tels que le framework MapReduce. MapReduce a été introduit par Google, et Hadoop en utilise une implémentation via le programme Pig. Il sert à faire des comptages de données, des calculs statistiques ou des classifications.
On a trouve également d'autres outils plus en amont tels que Hive permettant de requêter et d'analyser les données. Il est implémenté dans Hadoop.
Base de données
En bout de chaîne, on a des bases de données. Je citerai par exemple BigTable , Cassandra ou HBase qui piochent dans les technologies précédemment citées pour leur système de fichiers (GFS, HDFS) ou leur outil d'analyse.
Conclusion
On a l'impression que derrière Big Data se cache tous les développements spécifiques des gros consommateurs de données d'aujourd'hui (Google, Facebook, ...) et tout un tas de technologies différentes (systèmes de fichiers, frameworks, base de données) qui s'interconnectent totalement ou partiellement entre elles.
Le point à retenir du Big Data est la forte valeur donnée à la distribution et la parallélisation des traitements (Ce qui n'est pas une nouveauté en soi).
Les partenariats en cours vont-ils permettre de connaître une rationalisation des outils et la création d'une norme un peu plus claire dans l'avenir ? Rendez-vous dans deux ans :)
Big Data est un concept jeune et encore peu structuré, un peu comme ses bases de données finalement.
Alors une première remarque concernant Big Data : ce n'est pas une technologie précise, mais plutôt un concept qui désigne des ensembles de données extrêmement volumineux. Et derrière ce concept se cache donc différentes technologies et différentes problématiques tels que le stockages à travers des systèmes de fichiers (chose aujourd'hui mature et relativement transparente pour un utilisateur de bases de données relationnelles), et la manipulation de ces données.
Big Data est apparu pour répondre à la problématique des 3V (Velocity, Volume, Variety), problématique commençant à essouffler les SGBDR classiques, vu l'explosion des volumes de données lors de la dernière décennie.
Stockage de Fichiers
Le stockage des données s'effectue via des systèmes de fichiers distribués tels que Google File System (GFS) pour Google ou Hadoop Distributed File System (HDFS) pour Hadoop. Pourquoi avoir redéveloppé un système de fichiers et ne pas utiliser une base de données relationnelle classique à ce niveau là ? J'avoue que la question est ouverte, les SGBDR étant matures sur les clusters. Une réponse est peut-être de ne pas vouloir transformer et modifier les données avant stockage vu la volumétrie, donc gagner du temps. Cela permet de garder le format initial des données et donc de répondre aux problématiques de vitesse, volume et variété (3V).
Manipulation de données
Ici on retrouve les programmes qui effectuent les traitements ou les calculs sur les données, toujours via un processus de distribution et de parallélisation, tels que le framework MapReduce. MapReduce a été introduit par Google, et Hadoop en utilise une implémentation via le programme Pig. Il sert à faire des comptages de données, des calculs statistiques ou des classifications.
On a trouve également d'autres outils plus en amont tels que Hive permettant de requêter et d'analyser les données. Il est implémenté dans Hadoop.
Base de données
En bout de chaîne, on a des bases de données. Je citerai par exemple BigTable , Cassandra ou HBase qui piochent dans les technologies précédemment citées pour leur système de fichiers (GFS, HDFS) ou leur outil d'analyse.
Conclusion
On a l'impression que derrière Big Data se cache tous les développements spécifiques des gros consommateurs de données d'aujourd'hui (Google, Facebook, ...) et tout un tas de technologies différentes (systèmes de fichiers, frameworks, base de données) qui s'interconnectent totalement ou partiellement entre elles.
Le point à retenir du Big Data est la forte valeur donnée à la distribution et la parallélisation des traitements (Ce qui n'est pas une nouveauté en soi).
Les partenariats en cours vont-ils permettre de connaître une rationalisation des outils et la création d'une norme un peu plus claire dans l'avenir ? Rendez-vous dans deux ans :)
Big Data est un concept jeune et encore peu structuré, un peu comme ses bases de données finalement.
mercredi 4 juillet 2012
Le Livre du Mois : DataVision de David McCandless

Un petit bouquin pour les vacances, sur le sujet en vogue du moment : la Data Vizualisation ou DataViz.
Alors c'est un bouquin qui contient des rendus d'études statistiques, un peu "hype". Quelques exemples :


Je vous donne le pitch de la Fnac :
Chaque jour, nous risquons l'asphyxie, la noyade, inondés que nous sommes par l'information. La télévision, les journaux, le Web déversent désormais des flots ininterrompus de données, de chiffres, de prévisions. Dans cette masse, lorsqu'on trouve un schéma clair, une illustration lumineuse, un graphique explicite, c'est le soulagement, l'île au cœur de la tempête. Le design, en révélant la beauté cachée de l'information, nous aide à la comprendre, à la hiérarchiser, à la mémoriser. Comment ? Grâce à la puissance de notre œil. La vue est de loin le plus rapide et le plus puissant de nos sens. Et l'œil est délicieusement sensible aux variations de couleurs, de formes et de motifs. Il aime ce qui est beau. L'esprit, quant à lui, s'accroche d'abord aux mots, aux chiffres et aux concepts. Et si l'on combine le langage de l'œil avec celui de l'esprit, les deux langages, utilisés simultanément, s'enrichissent l'un l'autre. Et tout ? ou presque ? devient lumineux. C'est ainsi que ce livre fait la magistrale démonstration que l'on peut comprendre et mémoriser en un clin d'œil les sept chakras, l'évolution du mariage en Occident, le pourcentage d'étudiants vierges par disciplines universitaires, la conception fonctionnaliste de la conscience, la généalogie du rock et mille autres informations cruciales ou triviales. A vous de voir.
et le blog de l'auteur : David McCandless
C'est vraiment joli et sympa (et le bouquin est pas cher en plus :) ). Il y a malheureusement (ou heureusement peut-être vu la charge de développements que ça demanderait) peu d'applications directes avec la BI, car ce sont beaucoup de rendus statiques.
Néanmoins, on retrouve certaines choses implémentées dans des solutions de reporting : je pense aux treemaps par exemple :

J'en profite pour faire un peu de pub à Djeepy qui a écrit un article sur ce phénomène, et notamment un compte-rendu d'une conférence sur le sujet.
mardi 20 mars 2012
1er AfterWork de la communauté SQL Server BI
Le Groupe
Utilisateur SQL Server et FrenchConnection.BI lancent
leur premier Afterwork.
Venez discutez avec des
experts SQL Server autour d’un verre sur les sujets qui vous intéressent.
La
soirée sera sur le thème :
Self-Service BI
Jeudi 22 mars à partir de 19h30
Self-Service BI
Jeudi 22 mars à partir de 19h30
Elle sera animée par des
experts reconnus (François Jehl, Aurélien Koppel,
Florian Eiden, Jean-Pierre Riehl,
etc.).
Libres discussions,
échanges, et pourquoi pas des démos sur le thème de la Business Intelligence
mais également sur d’autres sujets sur lesquels vous voudriez échanger.
Retrouvons
nous au
Charly Birdy
place Étienne Pernet
Paris 15eme
place Étienne Pernet
Paris 15eme
La communauté SQL, c’est vous !
À noter que d’autres Afterwork auront lieu régulièrement sur tous les sujets SQL
qui vous tiennent à cœur (Big Data, Performances,
etc.)
mardi 7 février 2012
Le CRM en attendant la BI
Une petite news sympa où l'on apprend que Microsoft va sortir des applications CRM mobiles pour iOs ou Androïd (en plus bien sûr de Windows Phone 7).
Une première incursion en attendant des applications Business Intelligence ? On attend tous les outils sur iPad :)

Une première incursion en attendant des applications Business Intelligence ? On attend tous les outils sur iPad :)

vendredi 3 février 2012
[SSIS] Data Taps dans SSIS 2012
On continue la série d'articles sur les nouveautés SSIS dans SQL Server 2012 avec les data taps.

On a tous utilisé lors du développement de packages SSIS les data viewers qui nous permettaient de voir les données qui transitaient au sein d'un dataflow. Un des soucis des data viewers était leur utilisation limitée à la phase de développement : on ne pouvait pas l'utiliser sur nos environnements de productions. De plus lors de plantages, il nous arrivait de redescendre les packages sur notre environnement de développement et d'activer ces fameux data viewers, mais la désynchronisation des données entre les deux environnements compliquaient le travail de débogage.
Pour remédier à cela, Microsoft implémente dans SSIS 2012 les data taps. Ils permettent comme les data viewers de récupérer les données qui transitent, mais, en plus de les insérer dans des fichiers CSV. Autre avantage, ils ne nécessitent pas d'intervenir sur le package en lui-même, mais juste sur leur script d'exécution.
On imagine aisément leur utilisation lors d'un plantage en production pour vérifier les données réellement chargées.
En pratique
J'utilise comme support un package tout simple contenant un simple dataflow de chargement de données.

J'ai ainsi dans mon package deux data flow path :


On va voir que les noms des data flow path sont utiles par la suite.
Il ne reste alors qu'à scripter une instance d'exécution de mon package et d'ajouter les data taps et enfin de l'exécuter réellement. Pour cela on utilise 3 nouvelles procédure stockées :
L'architecture de mon projet SSIS est la suivante :

Le script est le suivant :



Conclusion
C'est vraiment une fonctionnalité intéressante qui risque d'être beaucoup utilisée sur les projets en cas d'anomalie de production. C'est le genre de petite nouveauté qui "ne mange pas de pain" mais qui montre l'évolution dans le bon sens d'Integration Services.

On a tous utilisé lors du développement de packages SSIS les data viewers qui nous permettaient de voir les données qui transitaient au sein d'un dataflow. Un des soucis des data viewers était leur utilisation limitée à la phase de développement : on ne pouvait pas l'utiliser sur nos environnements de productions. De plus lors de plantages, il nous arrivait de redescendre les packages sur notre environnement de développement et d'activer ces fameux data viewers, mais la désynchronisation des données entre les deux environnements compliquaient le travail de débogage.
Pour remédier à cela, Microsoft implémente dans SSIS 2012 les data taps. Ils permettent comme les data viewers de récupérer les données qui transitent, mais, en plus de les insérer dans des fichiers CSV. Autre avantage, ils ne nécessitent pas d'intervenir sur le package en lui-même, mais juste sur leur script d'exécution.
On imagine aisément leur utilisation lors d'un plantage en production pour vérifier les données réellement chargées.
En pratique
J'utilise comme support un package tout simple contenant un simple dataflow de chargement de données.

J'ai ainsi dans mon package deux data flow path :


On va voir que les noms des data flow path sont utiles par la suite.
Il ne reste alors qu'à scripter une instance d'exécution de mon package et d'ajouter les data taps et enfin de l'exécuter réellement. Pour cela on utilise 3 nouvelles procédure stockées :
- [catalog].[create_execution]
- [catalog].[add_data_tap]
- [catalog].[start_execution]
L'architecture de mon projet SSIS est la suivante :

J'ai créé ici 2 data taps, les valeurs de paramètres à renseigner sont assez explicites quand on regarde l'arborescence du projet SSIS. Les noms des data flow path sont à renseigner ici.
Il n'y a guère la valeur de la variable @task_package_path qui peut sembler plus obscure. On trouve la valeur à renseigner dans les propriétés du data flow task :

J'ai juste spécifié des noms de fichiers csv pour la variable @data_filename sans spécifier de dossier, il crée donc par défaut les fichiers dans le répertoire C:\Program Files\Microsoft SQL Server\110\DTS\DataDumps
Après exécution, on retrouve bien nos deux fichiers de données dans le répertoire mentionné.

Conclusion
C'est vraiment une fonctionnalité intéressante qui risque d'être beaucoup utilisée sur les projets en cas d'anomalie de production. C'est le genre de petite nouveauté qui "ne mange pas de pain" mais qui montre l'évolution dans le bon sens d'Integration Services.
mercredi 1 février 2012
[SSIS] Change Data Capture (CDC) dans SSIS 2012
Le change data capture est un concept qui n'est pas propre à SQL Server (présent dans d'autres SGBD tels que Oracle), et qui consiste à suivre et à récupérer les changements sur les données dans une table.
Il a été implémenté au niveau de SQL Server 2008, mais exclusivement au niveau du moteur de base de données : beaucoup d'articles de blog en ont parlé à l'époque, je vous invite à vous référer à l'article de François Jehl.
Un des côtés fastidieux du CDC était le traçage par LSN et donc l'écriture des requêtes qui pouvait être pénible sous SSIS.
Dans SQL Server 2012, Microsoft va plus loin dans sa démarche et nous donne 3 composants pour utiliser le CDC directement dans SSIS :







Package d'alimentation quotidien
On crée maintenant le package d'alimentation quotidien : il ressemble à notre package initial dans sa structure (toujours un CDC control task suivi d'un dataflow task et d'un autre CDC control task).
Dans le CDC Control Task Start on sélectionne "Get processing range" dans le "CDC control operation" :

Dans le CDC Control Task End, on sélectionne "Mark processing range" dans le "CDC control operation" :

Le dataflow task est maintenant développé de la manière suivante, à l'aide des deux nouveaux composants SSIS (CDC source et CDC splitter) :

Je m'attarde sur le CDC source, notamment au niveau du CDC processing mode. Je vous laisse consulter l'article suivant de Matt Masson (qui fait partie de l'équipe de développement de SSIS) pour comprendre pourquoi j'ai choisi "Net" :

J'effectue quelques requêtes de modifications de données dans ma table source et j'exécute ensuite mon package.
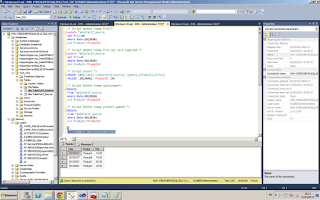
Dans mon dataflow, on retrouve bien les modifications effectuées sur ma table source, et ma table de destination est bien à la fin de l'exécution semblable à la table source :


Là où ça devient intéressant est que si vous relancez le package, aucune ligne n'est générée dans le dataflow. SSIS a géré tout seul les LSN grâce à nos CDC control task, et sait qu'il n'y a pas eu de changement pas rapport à la précédente exécution.

Conclusion :
SSIS 2012 implémente la gestion en natif du change data capture et simplifie son utilisation. La gestion pénible des LSN pour dater les changements devient implicite : aucune requête à écrire dans mon dataflow task au niveau des sources et aucune manipulation de dates à implémenter :
En revanche, il faut garder à l'esprit que le CDC peut être gourmand en ressources sur vos bases sources, comme c'était déjà le cas sur SQL Server 2008.
Il a été implémenté au niveau de SQL Server 2008, mais exclusivement au niveau du moteur de base de données : beaucoup d'articles de blog en ont parlé à l'époque, je vous invite à vous référer à l'article de François Jehl.
Un des côtés fastidieux du CDC était le traçage par LSN et donc l'écriture des requêtes qui pouvait être pénible sous SSIS.
Dans SQL Server 2012, Microsoft va plus loin dans sa démarche et nous donne 3 composants pour utiliser le CDC directement dans SSIS :
- Une tâche CDC Control Task qui va gérer le cycle de vie des packages CDC, et notamment toute la mécanique des LSN.
- Deux composants pour DataFlow Task, un CDC Source qui, comme son nom l'indique lit les informations d'une table de change data capture, et un CDC Splitter qui, lui va rediriger les lignes selon qu'elles doivent être insérées, mises à jour ou supprimées.
En pratique :
On va créer un package SSIS utilisant les composant CDC pour alimenter une table finale à partir d'une table source.
Je crée une table source de tarifs de produit dans laquelle j'insère un jeu de données test.

Sur cette table j'active le CDC. Ici c'est la même chose que sous SQL Server 2008, on retrouve les mêmes commandes.

Package d'initialisation
Dans SSIS, je crée mon package d'initialisation qui va effectuer la première alimentation de ma table destination et initialiser une variable d'état du CDC.
Le package se présente sous la forme suivante :

Les paramètres à saisir dans le CDC Control Task Start sont les suivants :
- Dans "SQL Server CDC database ADO.NET connection manager", renseigner le connection manager SSIS où est utilisé le change data capture
- Dans "CDC control operation", sélectionner "Mark initial load start"
- Dans "Variable containing the CDC state", donner le nom d'une variable où l'on va stocker l'état du CDC. Cliquer sur New s'il s'agit du premier appel.
- Les 3 champs suivants definissent respectivement la base de données, la table et le champ de la table où l'on stocke l'état du CDC

Le flux de contrôle "CDC Control Task End" est à configurer de la même manière, sauf que l'on sélectionne "Mark initial load end" dans "CDC control operation"
Le dataflow Task consiste en un bête chargement de table :
On peut dès lors exécuter le package et vérifier les données que j'ai dans ma table destination.

Package d'alimentation quotidien
On crée maintenant le package d'alimentation quotidien : il ressemble à notre package initial dans sa structure (toujours un CDC control task suivi d'un dataflow task et d'un autre CDC control task).
Dans le CDC Control Task Start on sélectionne "Get processing range" dans le "CDC control operation" :

Dans le CDC Control Task End, on sélectionne "Mark processing range" dans le "CDC control operation" :

Le dataflow task est maintenant développé de la manière suivante, à l'aide des deux nouveaux composants SSIS (CDC source et CDC splitter) :

Je m'attarde sur le CDC source, notamment au niveau du CDC processing mode. Je vous laisse consulter l'article suivant de Matt Masson (qui fait partie de l'équipe de développement de SSIS) pour comprendre pourquoi j'ai choisi "Net" :

J'effectue quelques requêtes de modifications de données dans ma table source et j'exécute ensuite mon package.

Dans mon dataflow, on retrouve bien les modifications effectuées sur ma table source, et ma table de destination est bien à la fin de l'exécution semblable à la table source :


Là où ça devient intéressant est que si vous relancez le package, aucune ligne n'est générée dans le dataflow. SSIS a géré tout seul les LSN grâce à nos CDC control task, et sait qu'il n'y a pas eu de changement pas rapport à la précédente exécution.

Conclusion :
SSIS 2012 implémente la gestion en natif du change data capture et simplifie son utilisation. La gestion pénible des LSN pour dater les changements devient implicite : aucune requête à écrire dans mon dataflow task au niveau des sources et aucune manipulation de dates à implémenter :
En revanche, il faut garder à l'esprit que le CDC peut être gourmand en ressources sur vos bases sources, comme c'était déjà le cas sur SQL Server 2008.
vendredi 27 janvier 2012
[Modélisation BI] Les Clés Etrangères
Relançons le débat pour un vendredi : faut-il mettre des clés étrangères dans un datawarehouse.
Sujet sensible puisque deux sessions aux dernières journées SQL Server en ont plus ou moins parlé :
Comme Florian le suggère sur son blog, vous devinerez que je suis partisan de ne pas en mettre.
Pourquoi une telle hérésie ?
Je fais de l'informatique décisionnelle : ma base de données se charge via des batchs uniques développés majoritairement avec SSIS (tout du moins pour mon cas). Mes tables n'ont donc qu'une façon unique d'être alimentée et ce qu'on insère doit, de ce fait, être totalement maîtrisé par mon package (voir mon article sur la gestion des orphelins à ce sujet).
C'est un point essentiel de ma démonstration : losrque je fais du développement SQL pour une application .NET par exemple, je mets des clés étrangères car mes tables peuvent dépendre à la fois de batch ou d'écrans de l'application, etc.
L'autre point essentiel est l'optimisation de mes traitements : la fenêtre temporelle pour le chargement des données est par expérience de plus en plus réduite et le volume des données toujours plus grand. Toute optimisation de chargement est donc bonne à prendre.
C'est pour cela également que je ne fais pas un un rejet total de toutes les contraintes : j'implémente des clés primaires et des index uniques bien pensés au niveau de mon datawarehouse
Et l'intégrité des données dans tout ça ?
Garantir l'intégrité des données par des relations de clés étrangères c'est bien, mais ça peut être coûteux en performance. Développer une solution d'alimentation qui ne permet pas de créer des problèmes d'intégrité, c'est mieux.
Il faut garder à l'esprit que vous devrez de toute façon repasser sur votre alimentation et redévelopper vos packages si vous avez des données non intègres. Les clés étrangères ne vous épargneront pas ce travail, donc autant y remédier en amont.
Et concrètement dans la pratique ?
Les conditions de test sont les suivantes :
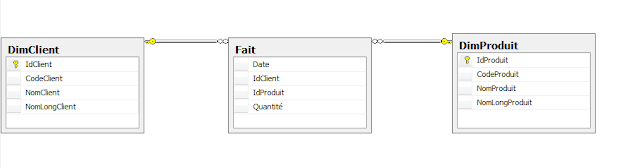
J'ai imaginé une table de faits avec un idTemps, un IdClient, un IdProduit et une quantité.
Un index unique sur les Id est créé.

Le premier test consiste en un chargement de 250000 lignes dans la table de faits lorsque celle-ci est vide.
Résultats :
Je ne prétends pas clore le débat avec cet article, mais juste exposer mes préférences et les argumenter. Il faut garder à l'esprit que les tests effectués ici sont faits sur une faible volumétrie et seulement deux clés étrangères.
Il convient enfin de garantir que votre solution d'alimentation empêche l'insertion de données non intègres pour pouvoir justifier la non-utilisation des clés étrangères.
Sujet sensible puisque deux sessions aux dernières journées SQL Server en ont plus ou moins parlé :
- La session de Florian Eiden et Jean-Pierre Riehl sur la modélisation dimensionnelle
- La session de Frédéric Brouard sur les contraintes et performances
Comme Florian le suggère sur son blog, vous devinerez que je suis partisan de ne pas en mettre.
Pourquoi une telle hérésie ?
Je fais de l'informatique décisionnelle : ma base de données se charge via des batchs uniques développés majoritairement avec SSIS (tout du moins pour mon cas). Mes tables n'ont donc qu'une façon unique d'être alimentée et ce qu'on insère doit, de ce fait, être totalement maîtrisé par mon package (voir mon article sur la gestion des orphelins à ce sujet).
C'est un point essentiel de ma démonstration : losrque je fais du développement SQL pour une application .NET par exemple, je mets des clés étrangères car mes tables peuvent dépendre à la fois de batch ou d'écrans de l'application, etc.
L'autre point essentiel est l'optimisation de mes traitements : la fenêtre temporelle pour le chargement des données est par expérience de plus en plus réduite et le volume des données toujours plus grand. Toute optimisation de chargement est donc bonne à prendre.
C'est pour cela également que je ne fais pas un un rejet total de toutes les contraintes : j'implémente des clés primaires et des index uniques bien pensés au niveau de mon datawarehouse
Et l'intégrité des données dans tout ça ?
Garantir l'intégrité des données par des relations de clés étrangères c'est bien, mais ça peut être coûteux en performance. Développer une solution d'alimentation qui ne permet pas de créer des problèmes d'intégrité, c'est mieux.
Il faut garder à l'esprit que vous devrez de toute façon repasser sur votre alimentation et redévelopper vos packages si vous avez des données non intègres. Les clés étrangères ne vous épargneront pas ce travail, donc autant y remédier en amont.
Et concrètement dans la pratique ?
Les conditions de test sont les suivantes :
- Machine Virtuelle en Windows 7
- SQL Server 2008
- 4 CPU
- 3 Go de Ram
J'ai imaginé une table de faits avec un idTemps, un IdClient, un IdProduit et une quantité.
Un index unique sur les Id est créé.

J'utilise un package SSIS d'upsert classique développé avec un double lookup.
Le premier test consiste en un chargement de 250000 lignes dans la table de faits lorsque celle-ci est vide.
Résultats :
| Sans clé étrangère | Avec clés étrangères |
| 6s078 | 7s458 |
Le second test consiste en un chargement de 250000 lignes dont la moitié sont en update et l'autre moitié sont en insert.
Résultats :
| Sans clé étrangère | Avec clés étrangères |
| 1min32 | 1min39 |
Conclusion :
Je ne prétends pas clore le débat avec cet article, mais juste exposer mes préférences et les argumenter. Il faut garder à l'esprit que les tests effectués ici sont faits sur une faible volumétrie et seulement deux clés étrangères.
Il convient enfin de garantir que votre solution d'alimentation empêche l'insertion de données non intègres pour pouvoir justifier la non-utilisation des clés étrangères.
jeudi 26 janvier 2012
SQL Server 2012 et Techdays 2012

Un petit message pour faire le point sur SQL Server 2012 :
La date de sortie est prévue pour le 7 Mars 2012
A ce sujet, je vous conseille de jeter un oeil sur le blog de Charles-Henri Sauget si vous souhaitez vous installer une maquette sur une machine virtuelle. Il consacre une série d'articles qui va de l'installation de SQL Server jusqu'à la production des rapports, et ceci de manière très bien détaillée.

Autre actualité autour des technologies Microsoft et donc de SQL Server 2012, la tenue des Techdays 2012, les 7, 8 et 9 Février au Palais des Congrès à Paris.
Beaucoup de sessions autour de SQL Server 2012 de prévues, année de sortie oblige :
- 2012 : les utilisateurs prennent le pouvoir ?
- Analysis Services 2012 : BI Personnelle, couche sémantique, cube, quelle(s) solution(s) pour un nouveau projet décisionnel?
- Business Intelligence ou Intelligence pour le Business avec SQL 2012 ?
- Mettre en Oeuvre une Plateforme d'Intégration et de Gestion des Informations de l'Entreprise (EIM) avec SQL Server 2012 Master Data Services
- Le futur a-t-il besoin de nous ?
- Vous avez dit Power View ?
- BI en libre-service et maîtrise de l'IT, pourquoi choisir ?
- SQL Server 2012: Gérer vos données maitres avec Master Data Services (MDS)
- SQL Server 2012 : Gérez la qualité de vos données avec Data Quality Services (DQS)
Je serai sûrement présent les 8 & 9 Février et j'essaierai d'assister aux sessions précédemment citées. Il y a de fortes chances que je traîne souvent avec Florian Eiden également.
Inscription à :
Articles (Atom)